Client: a talent sourcing company that matches professionals with client projects.
Role: Sole developer, end-to-end.
TL;DR
Built a conversational AI agent for a talent platform that transforms how clients find and hire professionals. Replaced a slow, manual, keyword-based search process with a fully agentic system that chats with users, understands their hiring needs, searches a vector-enabled talent database semantically, and returns a prioritised shortlist of best-fit candidates — all within a natural back-and-forth conversation. The result is a dramatically faster, smarter, and more interactive talent discovery experience that also recommends packaged hiring and delivery services where relevant.
Challenge
Recruiting the right talent from a large internal pool is time-consuming, error-prone, and heavily dependent on recruiter intuition. The client — a talent platform managing a database of vetted professionals — was relying on a manual, keyword-driven workflow to match clients with suitable candidates. This process was slow, missed nuanced skill overlaps, and offered no conversational experience for end users to refine or explore results.
Compounding the technical problem was a poorly structured legacy database schema, making even basic queries unreliable and limiting the ability to build intelligent tooling on top of the existing data.
My Approach
The project was executed in five interconnected phases, transforming a rudimentary static demo into a fully conversational, agentic talent-matching system.
-
Database Migration & Schema Redesign: The first priority was a clean foundation. The legacy PostgreSQL schema — hosted on Amazon RDS — was audited, and a new, well-structured schema was designed to properly capture talent profiles including contact details, skills, work experience, and project history. A custom migration pipeline transferred all existing records to the new structure on RDS without data loss.
-
Vector-Enabled Talent Database (PGVector on Amazon RDS): Rather than introducing a separate vector database service, the existing Amazon RDS PostgreSQL instance was extended with the PGVector extension — keeping infrastructure consolidated and costs low. Talent profiles were embedded using Mistral's embeddings model and stored alongside rich metadata. This enabled hybrid search: combining semantic similarity (e.g. "find someone who understands distributed systems") with precise metadata filtering across location, availability, and experience level.
-
LangChain Agent with Specialised Tools: A single-agent architecture was built using LangChain, connected with Mistral and Gemini APIs, equipped with three core tools: a hybrid talent search tool querying PGVector, a ranking and shortlisting tool reducing 20–40 candidates to a focused prioritised list, and a structured output tool formatting results as talent cards for the frontend. The agent reasons over user intent before deciding which tools to invoke and in what sequence.
-
Backend API with Hono: A lightweight, high-performance API layer was built using Hono on Node.js. This endpoint manages request routing between the Next.js frontend and the LangChain agent, handling session context, streaming responses, and file input processing.
-
Conversational Frontend (Next.js): The final interface allows users to chat naturally with the agent — asking follow-up questions, uploading job description files, and seeing shortlisted talent rendered as interactive profile cards. The experience mirrors a dialogue with a knowledgeable recruiter rather than a search bar.
Results & Impact
Estimated 40% reduction in time spent to find the best-fitting talents. Estimated 35% cost savings in the long term because of using an open source vector database.
The transformation from demo to production agent delivered measurable capability improvements across every dimension of the user experience:
| Before | After |
|---|---|
| Single-turn: one query, one static output | Multi-turn conversation — iterates with user needs |
| No follow-up or clarification possible | Accepts clarifying questions and refines results |
| Rigid talent list, no context-awareness | Context-aware shortlist of best-fit talents |
| Rigid packaged service recommendations, no context-awareness | Context-aware service recommendations, with adjustable deliverables and pricing |
| Manual keyword matching on old DB schema | Hybrid semantic + metadata search via PGVector |
Infrastructure Cost Efficiency: By extending the existing Amazon RDS PostgreSQL instance with PGVector rather than adopting a dedicated vector database service such as Pinecone or Weaviate, the solution avoids recurring SaaS licensing costs entirely. All vector storage and retrieval runs within infrastructure the client already operates — a deliberate architectural choice that reduces long-term operational overhead.
Talent Discovery Quality: The shift from keyword matching to hybrid semantic search means candidates are surfaced based on the meaning of their experience — not just exact-string matches on job titles or skill tags. This reduces missed matches and surfaces talent that would otherwise have been overlooked.
Visual Assets
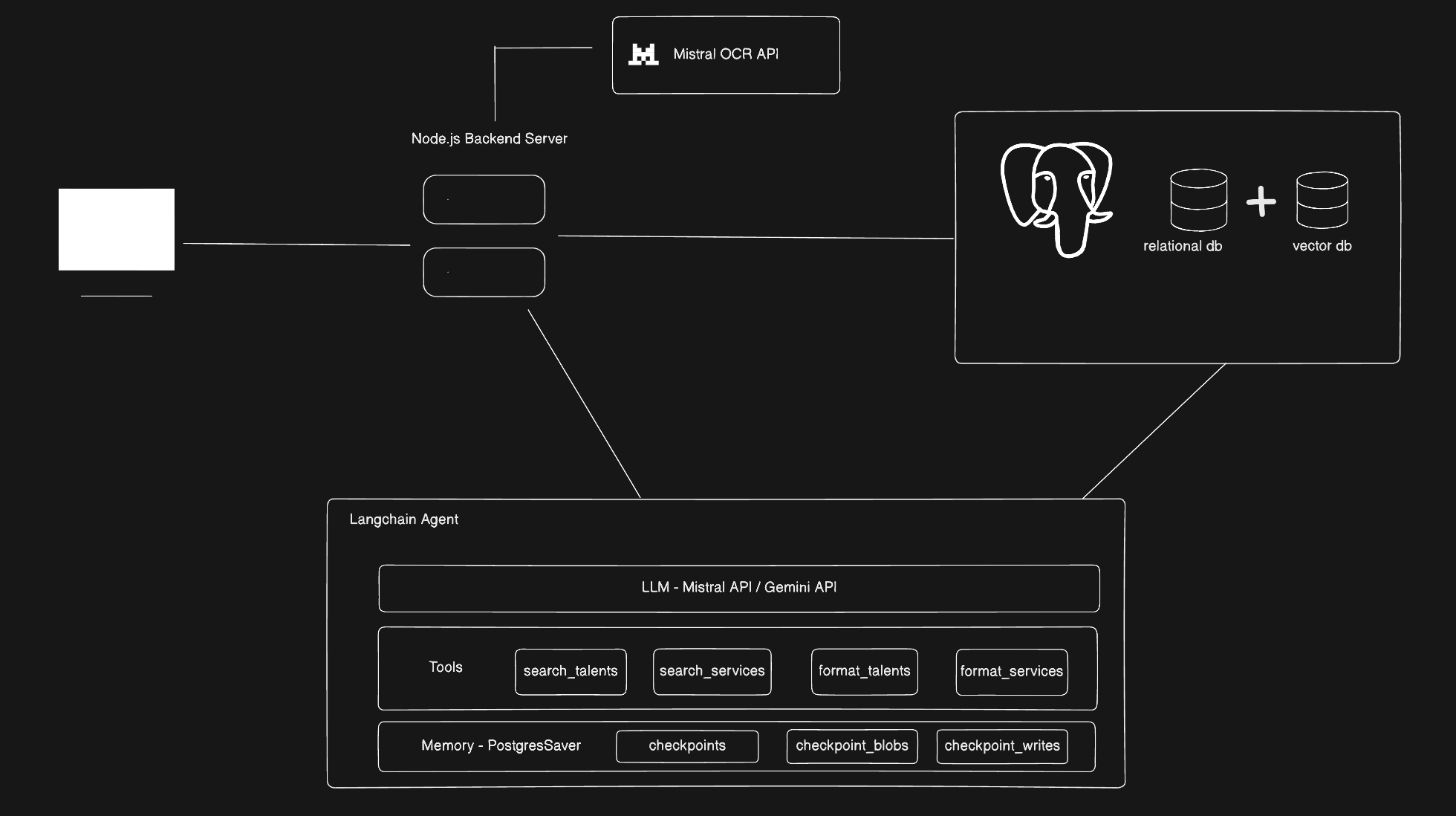 Architecture of the AI-powered Talent Sourcing Agent
Architecture of the AI-powered Talent Sourcing Agent
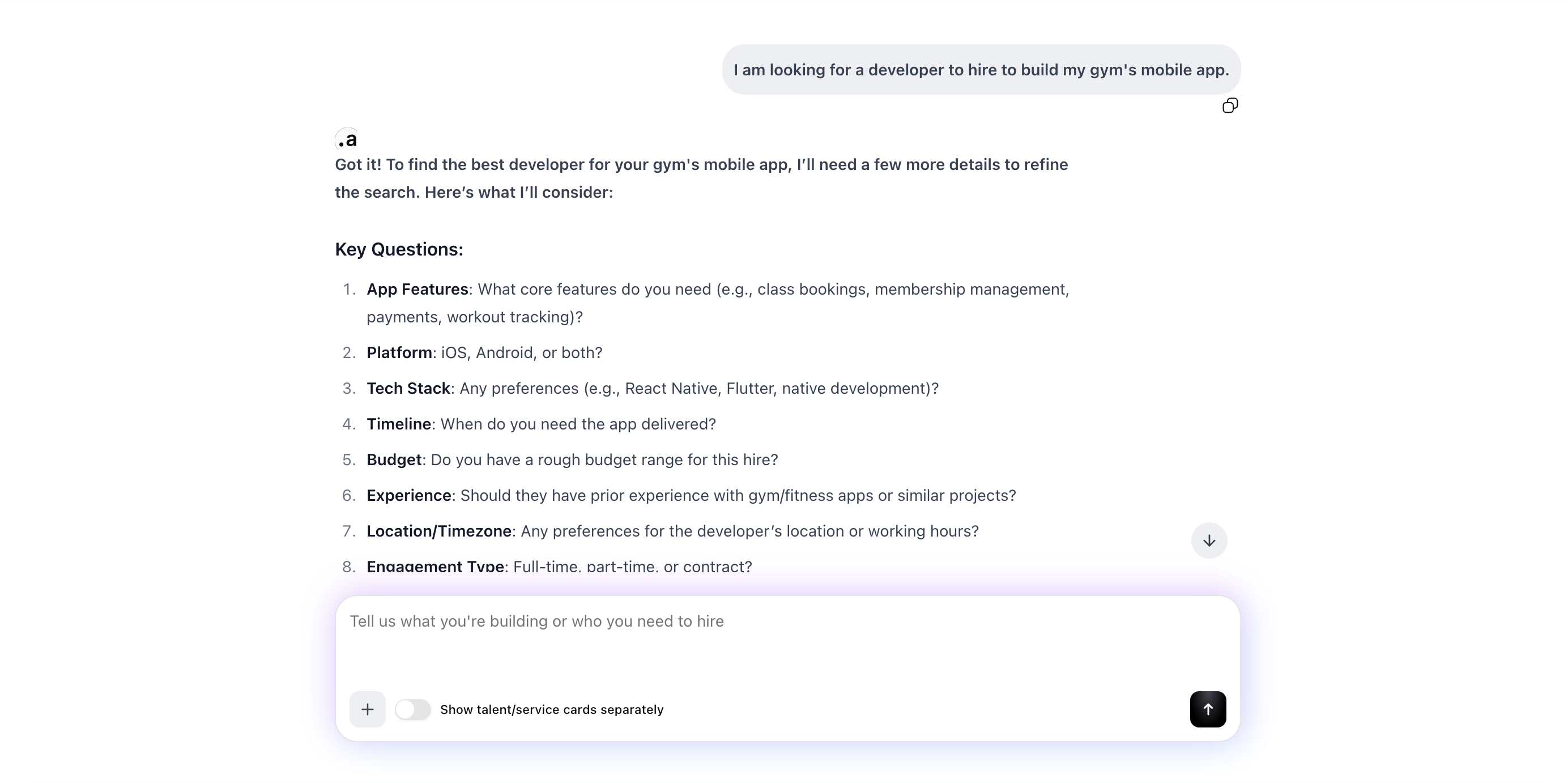 User chatting with the agent asking for a mobile app developer
User chatting with the agent asking for a mobile app developer
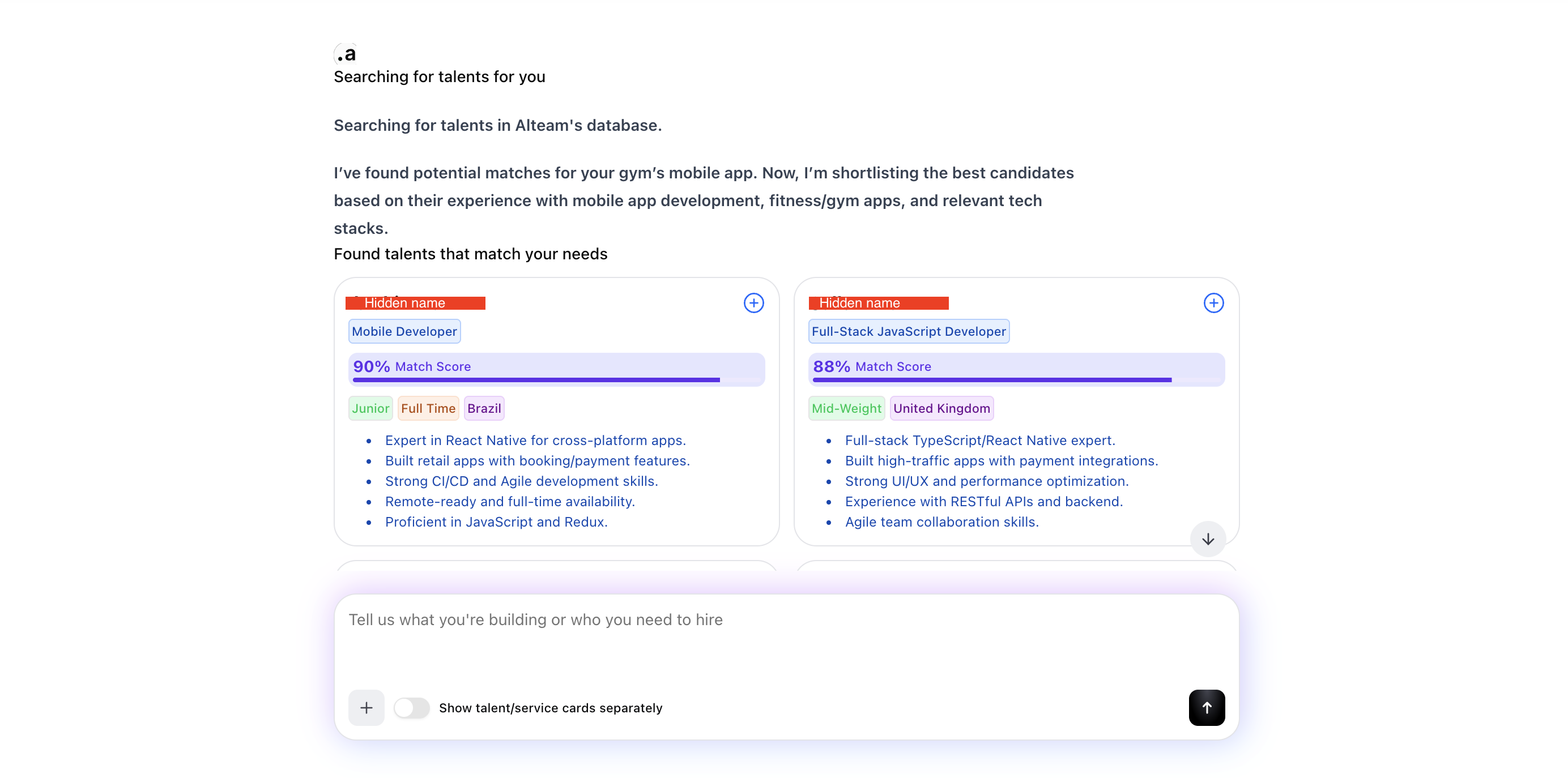 The agent showing recommended talents after searching through the database
The agent showing recommended talents after searching through the database
Tech Stack
- Language / Runtime: TypeScript, Node.js
- AI / Agent Framework: LangChain
- LLM: Gemini Flash 3/Mistral Small Latest
- Vector Database: PostgreSQL + PGVector (open-source, hosted on Amazon RDS)
- Embeddings: Mistral Embeddings API
- Search Strategy: Hybrid search (semantic similarity + metadata filtering)
- Backend Framework: Hono (Node.js)
- Frontend: Next.js (React)
- Database & Hosting: PostgreSQL on Amazon RDS
- Data Migration: Custom migration scripts (PostgreSQL → PostgreSQL on RDS)
Additional Context
This project began as an internal demo with limited conversational capability. The scope was subsequently expanded to a production-grade agentic system, requiring both infrastructure rework — database migration, schema redesign, and vector extension on Amazon RDS — and full-stack application development across the agent, API, and frontend layers.
The PGVector-on-RDS approach is also worth highlighting as an architectural pattern: it delivers vector search capabilities without the operational complexity or cost of a managed vector database, making it a practical choice for products that already run PostgreSQL on AWS.